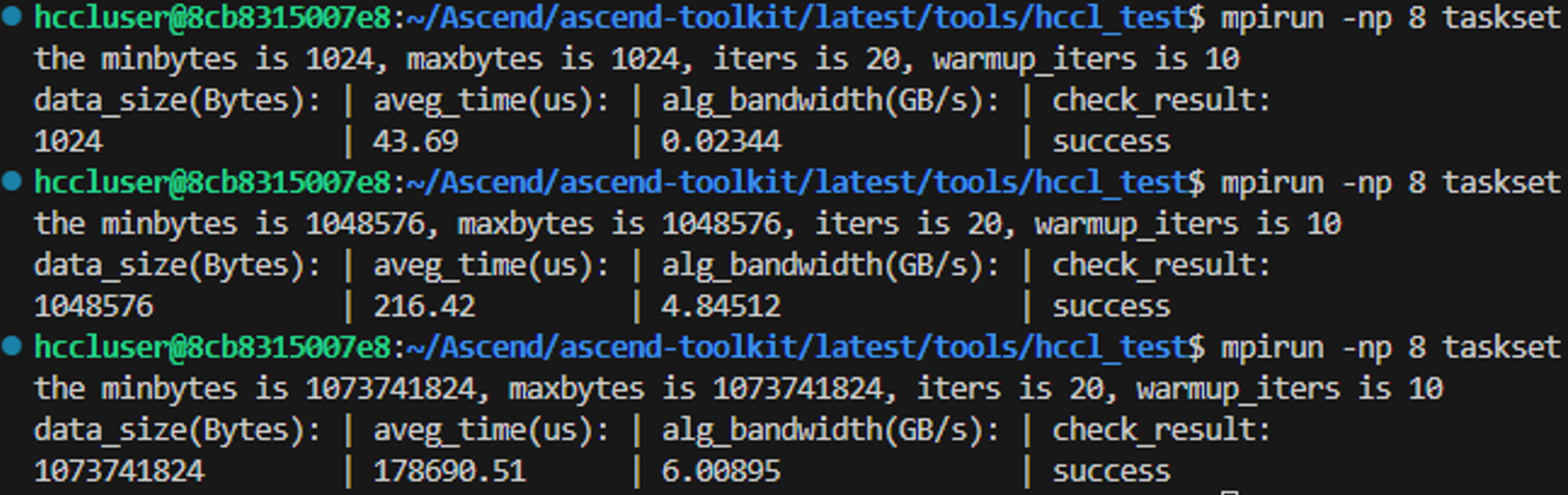
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
|
#include "coll_custom_small_all_reduce_mesh_executor.h"
namespace hccl
{
CollCustomSmallAllReduceMeshExecutor::CollCustomSmallAllReduceMeshExecutor(const HcclDispatcher dispatcher, std::unique_ptr<TopoMatcher> &topoMatcher)
: CollAllReduceExecutor(dispatcher, topoMatcher)
{
CCLMemSlice_ = false;
DMAReduceFlag_ = true;
}
// Calculate the amount of scratch memory to request
HcclResult CollCustomSmallAllReduceMeshExecutor::CalcScratchMemSize(u64 &scratchMemSize)
{
scratchMemSize = 0U;
HCCL_WARNING("[HCCLContest][CollCustomSmallAllReduceMeshExecutor][CalcScratchMemSize] scratchMemSize: %u",
scratchMemSize);
return HCCL_SUCCESS;
}
// Calculate the number of streams to be requested
HcclResult CollCustomSmallAllReduceMeshExecutor::CalcStreamNum(u32 &streamNum)
{
streamNum = 0U;
HCCL_WARNING("[HCCLContest][CollCustomSmallAllReduceMeshExecutor][CalcStreamNum] streamNum: %u", streamNum);
return HCCL_SUCCESS;
}
// Calculate the number of Notify to be requested
HcclResult CollCustomSmallAllReduceMeshExecutor::CalcNotifyNum(u32 streamNum, u32 ¬ifyNum)
{
notifyNum = 0U * streamNum;
HCCL_WARNING("[HCCLContest][CollCustomSmallAllReduceMeshExecutor][CalcNotifyNum] notifyNum: %u", notifyNum);
return HCCL_SUCCESS;
}
// Set up the level-0 mesh topology required for the AllReduce operation
HcclResult CollCustomSmallAllReduceMeshExecutor::CalcCommInfo(std::vector<LevelNSubCommTransport> &opTransport)
{
HCCL_WARNING("[HCCLContest][CollCustomSmallAllReduceMeshExecutor][CalcNotifyNum]");
// Define the source and destination memory types for communication
TransportMemType inputType = TransportMemType::CCL_INPUT;
TransportMemType outputType = TransportMemType::CCL_OUTPUT;
// Construct a mesh topology for level 0
CommParaInfo commParaLevel0(COMM_LEVEL0, CommType::COMM_TAG_MESH);
commParaLevel0.meshSinglePlane = true;
// Compute and populate the transport plan for level-0 communication domain
CHK_RET(CalcCommPlaneInfo(tag_, commParaLevel0, opTransport[COMM_LEVEL0], inputType, outputType));
return HCCL_SUCCESS;
}
// Calculate the number of iterations for loop processing
u64 CollCustomSmallAllReduceMeshExecutor::CalcLoopMaxCount(const u64 cclBuffSize, const u32 unitSize)
{
u64 maxCountPerLoop = cclBuffSize / unitSize;
HCCL_WARNING("[HCCLContest][CollCustomSmallAllReduceMeshExecutor][CalcLoopMaxCount] maxCountPerLoop: %u",
maxCountPerLoop);
return maxCountPerLoop;
}
// Process data for a single iteration of the AllReduce algorithm execution
HcclResult CollCustomSmallAllReduceMeshExecutor::KernelRun(const OpParam ¶m, ExecMem &execMem)
{
// Get sub-communication domain information for level 0
CHK_RET(CheckCommSize(COMM_LEVEL0, COMM_INDEX_0 + 1));
SubCommInfo level0CommInfo = GetSubCommInfo(COMM_LEVEL0, COMM_INDEX_0);
// Perform AllReduce
PerformButterfly(param, execMem);
HCCL_WARNING("[HCCLContest][CollCustomSmallAllReduceMeshExecutor][KernelRun] localRank: %u, localRankSize: %u",
level0CommInfo.localRank, level0CommInfo.localRankSize);
return HCCL_SUCCESS;
}
// Perform AllReduce by Butterfly
HcclResult CollCustomSmallAllReduceMeshExecutor::PerformButterfly(const OpParam ¶m, ExecMem &execMem)
{
// Get sub-communication domain information for level 0
CHK_RET(CheckCommSize(COMM_LEVEL0, COMM_INDEX_0 + 1));
SubCommInfo level0CommInfo = GetSubCommInfo(COMM_LEVEL0, COMM_INDEX_0);
// Dertermine the information for the topology
u32 rankSize = level0CommInfo.localRankSize;
u32 rankIdx = level0CommInfo.localRank;
// Determine unit size, chunk size for this iteration (unit: bytes)
u32 unitSize = SIZE_TABLE[param.DataDes.dataType];
u64 chunkSize = execMem.count * unitSize;
// Retrieve the master stream
hccl::Stream &masterStream = const_cast<hccl::Stream &>(param.stream);
// Prepare for the memory device
DeviceMem userInMem = DeviceMem::create(execMem.inputPtr, chunkSize);
DeviceMem cclOutMem = execMem.outputMem.range(0, chunkSize);
DeviceMem userOutMem = DeviceMem::create(execMem.outputPtr, chunkSize);
// Perform Butterfly
u32 nSteps = static_cast<u32>(log2(rankSize));
for (u32 step = 0; step < nSteps; step++)
{
// Calculate the remote rank for this step
u32 logicalRankIdx = PhysicalToLogical(rankIdx, rankSize);
u32 logicalDstRankIdx = logicalRankIdx ^ (1 << step);
u32 dstRank = LogicalToPhysical(logicalDstRankIdx, rankSize);
// Prepare data for this step
if (step == 0)
{
// Copy data from user input to user output and CCL_Out
CHK_RET(HcclD2DMemcpyAsync(dispatcher_, userOutMem, userInMem, masterStream));
CHK_RET(HcclD2DMemcpyAsync(dispatcher_, cclOutMem, userInMem, masterStream));
}
else
{
// Copy data from user output to CCL_Out
CHK_RET(HcclD2DMemcpyAsync(dispatcher_, cclOutMem, userOutMem, masterStream));
}
// Notify the remote rank that it is ready
CHK_RET(level0CommInfo.links[dstRank]->TxAck(masterStream));
// Wait for the remote rank to be ready
CHK_RET(level0CommInfo.links[dstRank]->RxAck(masterStream));
// Reduce data from the remote rank's CCL_Out to local rank's user output
void *srcRemotePtr = nullptr;
CHK_RET(level0CommInfo.links[dstRank]->GetRemoteMem(UserMemType::OUTPUT_MEM, &srcRemotePtr));
DeviceMem srcRemote = DeviceMem::create(static_cast<u8 *>(srcRemotePtr), chunkSize);
CHK_RET(HcclReduceAsync(dispatcher_, srcRemote.ptr(), chunkSize / unitSize,
param.DataDes.dataType, param.reduceType,
masterStream, userOutMem.ptr(),
level0CommInfo.links[dstRank]->GetRemoteRank(),
level0CommInfo.links[dstRank]->GetLinkType(),
INLINE_REDUCE_BIT));
// Notify the remote rank that the transmission is finished
CHK_RET(level0CommInfo.links[dstRank]->TxDataSignal(masterStream));
// Wait for the remote rank to complete transmission
CHK_RET(level0CommInfo.links[dstRank]->RxDataSignal(masterStream));
}
return HCCL_SUCCESS;
}
// Convert logical rank addresses to actual rank addresses
u32 CollCustomSmallAllReduceMeshExecutor::LogicalToPhysical(u32 logicalRank, u32 rankSize)
{
return (logicalRank + 1) % rankSize;
}
// Convert actual rank addresses to logical rank addresses
u32 CollCustomSmallAllReduceMeshExecutor::PhysicalToLogical(u32 physicalRank, u32 rankSize)
{
return (physicalRank + rankSize - 1) % rankSize;
}
REGISTER_EXEC("CustomSmallAllReduceMeshExecutor", CustomSmallAllReduceMesh, CollCustomSmallAllReduceMeshExecutor);
} // namespace hccl
|