赛题回顾
环境:单机8卡昇腾910B服务器一台
赛题内容:在8PMesh中,断掉一根Full Mesh直连的路径(Rank0和Rank1之间的一根链路),完成AllReduce的集合通信语义
评分指标:使用算法分析工具验证,语义实现正确;在物理环境上运行HCCL Test工具,考察1KB、1MB、1GB这三种数据量下的算法带宽的均值,根据三种数据量下的算法带宽作为评判依据
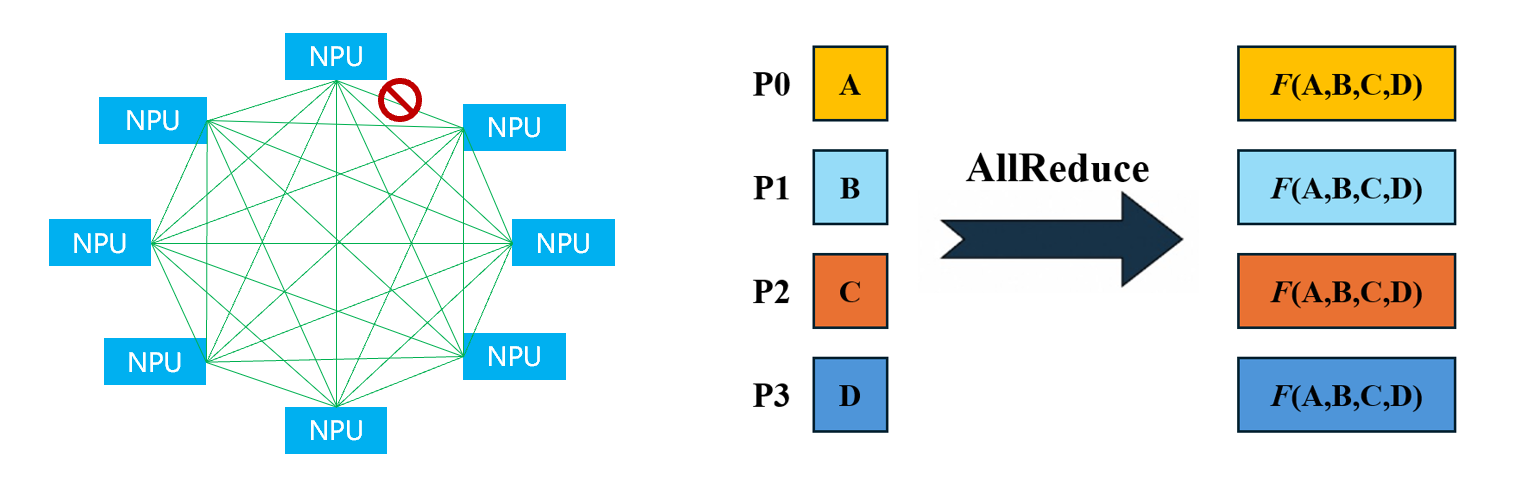
赛题分析
拓扑结构
机内采用Full Mesh拓扑,每块910B与机内其它7块910B直接互连,根据民间资料获知HCCS链路的带宽是56GB/s,因此聚合带宽可达392GB/s。查询了下机内拓扑发现拓扑正常,估计Rank0和Rank1之间的链路是通过HCCL代码在软件层面上屏蔽的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
$ npu-smi info -t topo
NPU0 NPU1 NPU2 NPU3 NPU4 NPU5 NPU6 NPU7 CPU Affinity
NPU0 X HCCS HCCS HCCS HCCS HCCS HCCS HCCS 144-167
NPU1 HCCS X HCCS HCCS HCCS HCCS HCCS HCCS 0-23
NPU2 HCCS HCCS X HCCS HCCS HCCS HCCS HCCS 144-167
NPU3 HCCS HCCS HCCS X HCCS HCCS HCCS HCCS 0-23
NPU4 HCCS HCCS HCCS HCCS X HCCS HCCS HCCS 96-119
NPU5 HCCS HCCS HCCS HCCS HCCS X HCCS HCCS 48-71
NPU6 HCCS HCCS HCCS HCCS HCCS HCCS X HCCS 96-119
NPU7 HCCS HCCS HCCS HCCS HCCS HCCS HCCS X 48-71
Legend:
X = Self
SYS = Path traversing PCIe and NUMA nodes. Nodes are connected through SMP, such as QPI, UPI.
PHB = Path traversing PCIe and the PCIe host bridge of a CPU.
PIX = Path traversing a single PCIe switch
PXB = Path traversing multipul PCIe switches
HCCS = Connection traversing HCCS.
|
直观分析
回到赛题本身,在 AllReduce 算法中,任务的总体性能受计算开销和通信开销共同影响。对于小数据量场景,单个节点的数据量较少,通信延迟和算法复杂度成为主要瓶颈,因此性能主要依赖于低延迟和低复杂度的设计。例如过多的分块、过深的递归或复杂的数据划分策略,可能导致每次通信的启动成本占据总体运行时间,从而降低性能。相比之下,通信开销在小数据量下通常占比不高,因此优化通信协议、减少迭代次数和算法复杂度是提高性能的关键。
在大数据量场景下,单个节点需要处理的数据量大,链路利用率和并行能力成为性能决定因素。此时的计算开销虽然相对增加,但通信带宽的利用效率对总耗时影响更显著。例如,如果网络带宽无法充分利用或者通信无法并行化,节点会在等待数据传输完成时出现空闲,导致整体性能下降。因此在大数据量下,优化AllReduce的关键是提高通信带宽利用率、合理安排并行计算与数据传输,从而最大化吞吐量,降低总执行时间。
数学分析
通信开销:
$$
T_\text{comm} = s \cdot \alpha + \frac{N}{P_\text{eff}} \cdot \beta
$$计算开销:
$$
T_\text{comp} = N \cdot \gamma
$$总耗时由通信开销和计算开销组成,合并总公式:
$$
\boxed{T_\text{allreduce} = s \cdot \alpha + \frac{N}{P_\text{eff}} \cdot \beta + N \cdot \gamma}
$$符号说明:
- \(N\):每个节点归约的数据量(元素数或字节数)
- \(s\):通信轮数,依赖算法拓扑
- \(\alpha\):每轮通信延迟
- \(\beta\):每字节通信开销(带宽倒数)
- \(P_\text{eff}\):每轮有效并行度或可用带宽比例
- \(\gamma\):每字节计算开销
总的来说,小数据量更看重延迟和算法轻量化,通信开销占主导;而大数据量更看重带宽利用和并行效率,通信与计算需要协同优化。
环境部署
编译所需的依赖项均已安装,在 HCCL 代码仓执行编译即可:
1
2
|
cd /home/hccluser/cann-hccl
bash build.sh --nlohmann_path /home/hccluser/nlohmann_json/include
|
编译生成的HCCL软件包在/home/hccluser/cann-hccl/output目录下,直接安装:
1
2
|
cd /home/hccluser/cann-hccl/output
./output/CANN-hccl_alg-8.2.t12.0.b077-linux.aarch64.run
|
执行 HCCL Test:
1
2
3
4
|
cd /home/hccluser/Ascend/ascend-toolkit/latest/tools/hccl_test
mpirun -np 8 taskset -c 0,2,4,6,8,10,12,14 ./bin/all_reduce_test -b 1k -e 1k -d fp32 -o sum -p 8
mpirun -np 8 taskset -c 0,2,4,6,8,10,12,14 ./bin/all_reduce_test -b 1m -e 1m -d fp32 -o sum -p 8
mpirun -np 8 taskset -c 0,2,4,6,8,10,12,14 ./bin/all_reduce_test -b 1g -e 1g -d fp32 -o sum -p 8
|
通过- w与- n参数设置预热次数和运行次数,通过重复多次运行获得可靠的性能平均值:
1
2
3
4
|
cd /home/hccluser/Ascend/ascend-toolkit/latest/tools/hccl_test
mpirun -np 8 taskset -c 0,2,4,6,8,10,12,14 ./bin/all_reduce_test -b 1k -e 1k -d fp32 -o sum -p 8 -w 100 -n 500
mpirun -np 8 taskset -c 0,2,4,6,8,10,12,14 ./bin/all_reduce_test -b 1m -e 1m -d fp32 -o sum -p 8 -w 100 -n 500
mpirun -np 8 taskset -c 0,2,4,6,8,10,12,14 ./bin/all_reduce_test -b 1g -e 1g -d fp32 -o sum -p 8 -w 100 -n 500
|
算法分析器在CPU上运行,逻辑验证算法正确性:
1
2
|
cd /home/hccluser/cann-hccl
bash build.sh --nlohmann_path /home/hccluser/nlohmann_json/include --test --open_hccl_test
|