
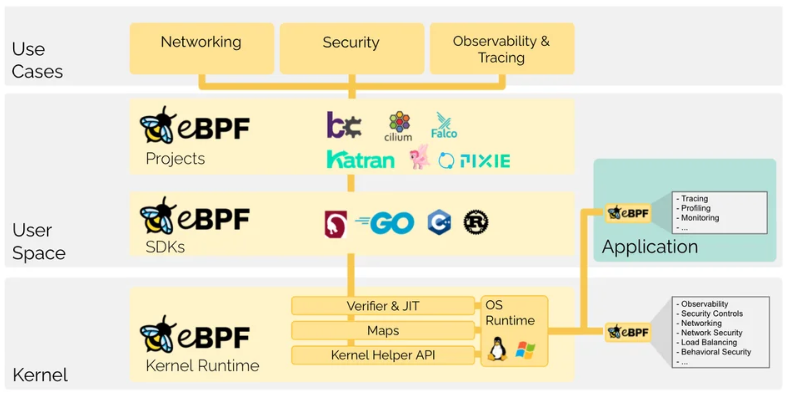
eBPF的发展历程
eBPF(Extended Berkeley Packet Filter)最初起源于BPF(Berkeley Packet Filter),BPF是1992年由Steven McCanne和Van Jacobson提出的,用于在内核空间中高效过滤网络数据包。最早的 BPF 是一种简易的虚拟机,只能运行非常有限的指令集,主要面向网络抓包工具。
到了2014年,Linux社区(以Alexei Starovoitov为主的开发者)将其扩展为eBPF,在Linux 3.18内核中正式引入。与经典BPF相比,eBPF拥有更强大的指令集、寄存器模型,并引入了内核级验证器,保证了运行安全性。随着内核版本演进,eBPF不再局限于网络包过滤,而是逐步扩展到:
- 性能分析:利用eBPF可以实现对系统调用、函数、事件的动态追踪;
- 网络可观测性与负载均衡:Cilium、Katran等项目基于eBPF实现了高效的容器网络与负载均衡;
- 安全性:例如由Cilium团队开发的Tetragon,可实时监控进程、网络行为,自动检测异常模式;
- 系统调优:在内核态对I/O、调度等行为进行动态优化。
到2020 年以后,eBPF社区更趋成熟,形成了丰富的生态,包括:eBPF核心内核特性、用户态工具链(bcc、libbpf、bpftool)、云原生集成(Kubernetes + Cilium)等。eBPF已被广泛用于网络、监控、安全、调试等多个领域,并成为Linux内核可观测性和可编程性的重要基石。
eBPF架构
eBPF通过允许在操作系统中运行沙盒程序的方式,应用程序开发人员可以运行eBPF程序,以便在运行时向操作系统添加额外的功能。然后在JIT编译器和验证引擎的帮助下,操作系统确保它像本地编译的程序一样具备安全性和执行效率。
eBPF程序本身是不会一直运行的,它是事件驱动的:当某个特定事件发生时才被触发执行,这个特定事件就是所谓的hook(钩子)。具体而言,hook是系统中预定义的一些事件触发点,当触发点发生时,eBPF程序就被触发执行。预定义的钩子包括系统调用、函数入口/退出、内核跟踪点、网络事件等:
- 系统调用syscall:用户态程序需要访问内核服务(例如读文件、创建进程、收发网络数据)时,必须通过内核提供的系统调用接口,例如open()、read()、write()、socket()、execve()等。eBPF可以把程序挂到系统调用入口,监控或记录每次调用时的参数、返回值,进而可以实现审计和安全策略,例如记录谁打开了哪个文件、检测是否执行了可疑命令。
- 函数入口/退出:指的是内核中任意函数的入口或返回点,eBPF程序可以通过kprobe、kretprobe捕获函数调用时的参数和返回值。因此比系统调用syscall钩子的粒度更细,可以追踪具体子模块的行为。
- 内核跟踪点tracepoint:内核开发者在一些关键位置里手动打好的埋点。
- 网络事件:该钩子使网络数据包在内核网络栈中经过的不同阶段,可以让eBPF程序介入这些阶段,对数据包进行检测、修改、统计、转发等操作。

eBPF程序的运行流程通常包括编写、编译、加载、验证、JIT编译及运行时交互等阶段:
- 开发者直接基于eBPF或更高层的工具(如bpftrace、bcc等实现了对eBPF功能的封装)开发实现eBPF程序逻辑;
- 随后利用LLVM/Clang工具链将其编译为与平台无关的eBPF字节码;
- 用户态的加载器通过bpf()系统调用将字节码加载至内核,并附加到特定的钩子上;
- 在加载的过程中,内核内置的验证器会对程序进行严格的分析,确保其满足安全与可终止性要求;
- 验证通过后,字节码将被JIT编译为本地指令,从而在事件触发时执行;
- 运行阶段中,eBPF程序通过调用内核提供的helper函数安全地访问系统信息,并借助eBPF maps与用户态程序进行状态共享与数据交互,实现对网络、安全或性能行为的动态监测与控制。
eBPF程序编写与编译
直接编写eBPF程序非常困难,涉及大量的底层操作,因此通常基于封装、更高抽象的开放框架进行开发,常见的包括:
- BCC:是开发eBPF程序最早的方式之一,支持开发者通过Python/C/C++多种语言编写eBPF程序;
- libbpf:是当下最热门的eBPF程序开发方式之一,为Linux内核源码的一部分;
- aya:使开发者通过Rust语言开发eBPF程序;
- cilium/ebpf:使开发者通过Go语言开发eBPF程序;
- libbpf-go:使开发者通过Go语言开发eBPF程序。
BCC与libbpf的区别:BCC是在CO-RE技术出现之前诞生的,是一个更动态化的运行时工具集。在BCC中,eBPF程序每次运行时,需要用Clang/LLVM在本地重新编译、生成字节码,因此机器上必须安装Clang、LLVM,并包含内核头文件,这种方式需要大量的存储和计算资源,也不利于不跨内核版本部署。libbpf从设计之初就原生支持CO-RE(Compile Once – Run Everywhere,一次编译、到处运行)技术,只需编译一次eBPF程序(.o 文件),即可在跨内核发行版、跨内核版本运行。
加载器和校验验证
加载器是在用户态运行的程序,负责读取eBPF程序的编译产物、使用系统调用bpf()加载到Linux内核。随后的验证步骤用来确保eBPF程序可以安全运行,它可以验证程序是否满足几个条件,例如:
- 加载eBPF程序的进程必须有所需的特权。除非启用非特权eBPF,否则只有特权进程可以加载eBPF程序;
- eBPF程序不会崩溃或者对系统造成损害;
- eBPF程序一定会运行至结束(即程序不会处于循环状态中,否则会阻塞进一步的处理);
- 程序不能使用任何未初始化的变量或越界访问内存;
- 程序必须符合系统的大小要求。不可能加载任意大的eBPF程序;
- 程序必须具有有限的复杂性。验证器将评估所有可能的执行路径,并且必须能够在最高复杂性限制范围内完成运行。
验证器通过后,eBPF字节码会被内核即时编译(Just-in-Time, JIT)为本地机器码,其执行效率接近内核模块。
Helper调用
eBPF程序运行在内核中的受控虚拟机环境里,不允许直接调用任意内核函数,原因主要有两点:
- 直接调用内核函数会将eBPF程序与特定内核版本的内部实现细节强绑定,内核升级或不同发行版间的差异都可能导致程序失效或产生不可预期行为,严重影响可移植性和可维护性;
- 直接调用内核函数缺乏严格的安全边界管理,可能导致内核崩溃、死锁、数据竞争或引入安全漏洞。
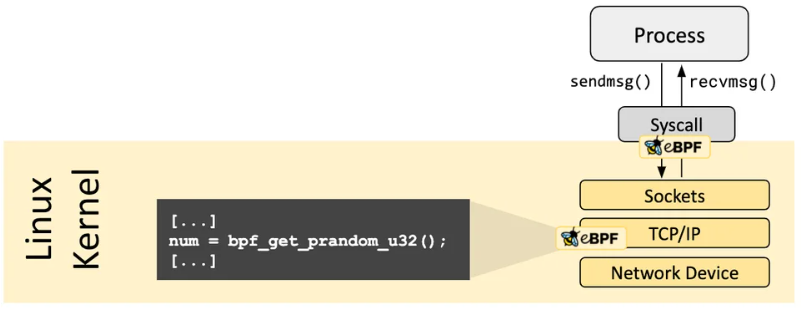
为此,eBPF提供了一个由内核实现和维护的Helper函数接口,作为 eBPF 程序与内核交互的唯一桥梁。Helper函数本质是经过安全审计、功能受限的官方API,既可以满足获取时间、访问 map、修改网络数据包等常用需求,又能确保安全性。通过这种设计,eBPF实现了与内核版本解耦:eBPF只需遵循Helper接口,同时各版本内核中保持该接口的稳定,eBPF即无需关心底层实现细节,增强了eBPF程序跨平台的可移植性。例如,eBPF程序获取随机数需使用bpf_get_prandom_u32()函数。
eBPF Maps
eBPF程序本身只在事件触发时短暂运行,需要依赖map来:存储运行时产生的数据;统计计数器、直方图、时延分布等。用户态进程也可通过系统调用与map交互,实现从eBPF程序收集观测数据、写入控制信息(例如动态更新限速阈值)。eBPF提供了多种类型的map,包括哈希表、数组、最长前缀匹配、环形缓冲区等复杂结构,能够满足不同性能与功能需求